jvm
多线程
语音识别
边缘计算
kotlin
JUC
gitlab
二次元
免责声明
Nanoprobes
产品经理培训
批量下载图片的插件
数据库通用命令
NOIP
django-redis
angular.js
游戏建模
finebi
AutoSar OS
pysimplegui
损失函数
2024/4/11 16:20:00
损失函数:IoU、GIoU、DIoU、CIoU、EIoU、alpha IoU、SIoU、WIoU超详细精讲及Pytorch实现
前言 损失函数是用来评价模型的预测值和真实值不一样的程度,损失函数越小,通常模型的性能越好。不同的模型用的损失函数一般也不一样。 损失函数的使用主要是在模型的训练阶段,如果我们想让预测值无限接近于真实值,就需要将损…

AI学习-线性回归推导
线性回归 1.简单线性回归2.多元线性回归3.相关概念熟悉4.损失函数推导5.MSE损失函数 1.简单线性回归
线性回归:有监督机器学习下一种算法思想。用于预测一个或多个连续型目标变量y与数值型自变量x之间的关系,自变量x可以是连续、离散,但是目标变量y必…
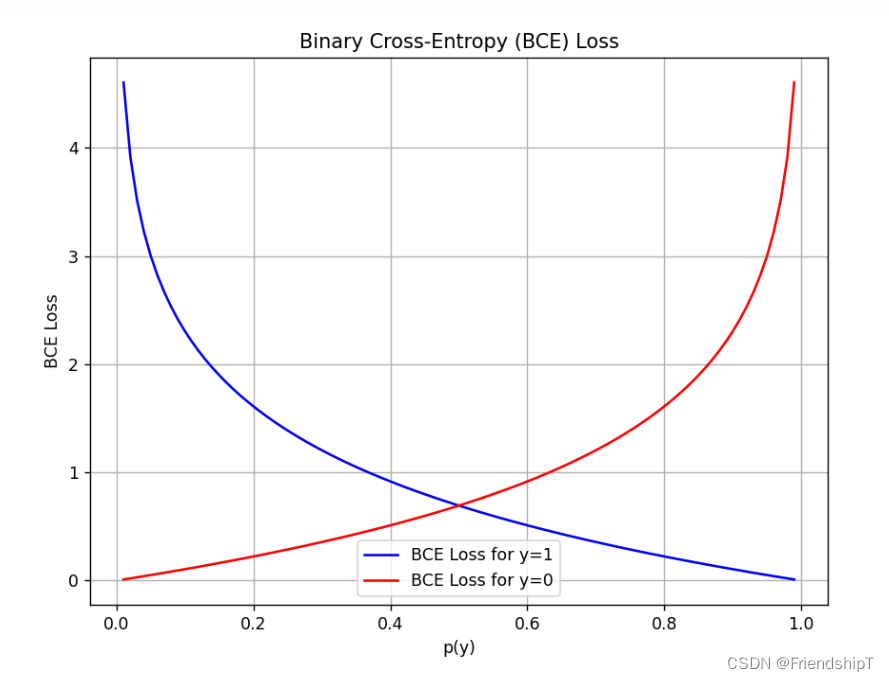
损失函数:BCE Loss(二元交叉熵损失函数)、Dice Loss(Dice相似系数损失函数)
损失函数:BCE Loss(二元交叉熵损失函数)、Dice Loss(Dice相似系数损失函数) 前言相关介绍BCE Loss(二元交叉熵损失函数)代码实例直接计算函数计算 Dice Loss(Dice相似系数损失函数&a…
机器学习笔记 - 从数学表示的角度看待监督学习
一、概述 监督学习的目标是根据数据进行预测。比如电子邮件垃圾邮件过滤,需要将电子邮件(数据实例)分类为垃圾邮件或非垃圾邮件。 按照传统计算机科学的方法,需要编写一个精心设计的程序,遵循一些规则来确定电子邮件是否是垃圾邮件。尽管这样的程序可能在一段时间内运行得…
机器学习5-线性回归之损失函数
在线性回归中,我们通常使用最小二乘法(Ordinary Least Squares, OLS)来求解损失函数。线性回归的目标是找到一条直线,使得预测值与实际值的平方差最小化。 假设有数据集 其中 是输入特征, 是对应的输出。 线性回归的…

【动手学深度学习】深入浅出深度学习之线性神经网络
目录
🌞一、实验目的
🌞二、实验准备
🌞三、实验内容
🌼1. 线性回归
🌻1.1 矢量化加速
🌻1.2 正态分布与平方损失
🌼2. 线性回归的从零开始实现
🌻2.1. 生成数据集
&#x…

李飞飞计算机视觉笔记(2)--线性分类器损失函数与最优化
文章中的词语解释: 分类器:完整的神经网络 类别分类器:分类器中的某一个输出对应的所有权值(单层全连接神经网络) 损失函数:不包括正则式的损失函数 正则化损失函数:包括正则式的损失函数 多类S…


Keras自定义损失函数在场景分类的使用
Keras自定义损失函数在场景分类的使用
在做图像场景分类的过程中,需要自定义损失函数,遇到很多坑。Keras自带的损失函数都在losses.py文件中。(以下默认为分类处理)
#losses.py
#y_true是分类的标签,y_pred是分类中预…

scratch lenet(12): LeNet-5输出层和损失函数的计算
文章目录 1. 目的2. 输出层结构2.1 Gaussian Connection2.2 Gaussian Connection 的 weight 可视化 3. Loss Function3.1 当前类别判断错误时,loss function 中的项(基本项)3.2 判断为其他类别时, loss function 中的项࿰…
神经网络中的损失函数(下)——分类任务
神经网络中的损失函数 前言分类任务中的损失函数交叉熵最大似然信息论信息量信息熵最短平均编码长度交叉熵 KL散度余弦相似度损失函数 总结 前言
上文主要介绍了回归任务中常用的几个损失函数,本文则主要介绍分类任务中的损失函数。
分类任务中的损失函数
为了与…
【损失函数】NLLLoss损失、CrossEntropy_Loss交叉熵损失以及Label Smoothing示例与代码
机缘巧合下,近期又详细学习了一遍各损失函数的计算,特此记录以便后续回顾。 为了公式表示更加清晰,我们设 yn∈{1,2,…,K}{{y_n} \in \{ 1,2, \ldots ,K\} }yn∈{1,2,…,K} 为样本 n{n}n 的真实标签,v(v1,v2,…vK){v ({v_1},{v…
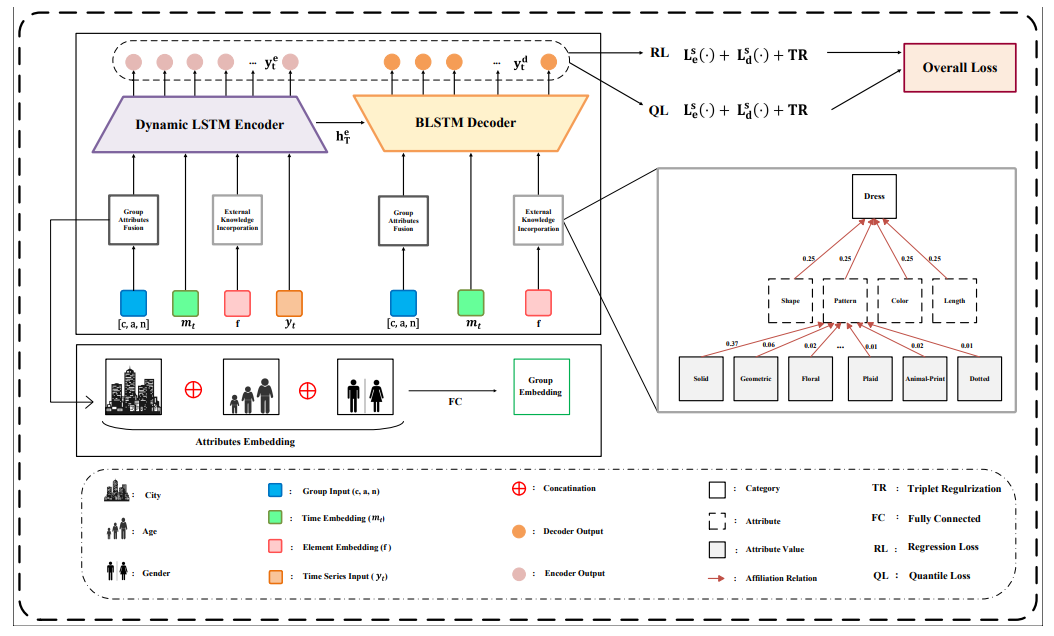
深度学习损失函数新成果!18个突破性方法,让模型更精准、更高效
基于最优传输思想设计的分类损失函数EMO解决了交叉熵损失函数在某些场景暴露的一些问题,如偏离评价指标、过度自信等,它源于交叉熵损失函数,能大幅提高 LLM 的微调效果。
交叉熵损失函数是最常用的一种损失函数。在机器学习中,损…
PyTorch官网demo解读——第一个神经网络(3)
上一篇:PyTorch官网demo解读——第一个神经网络(2)-CSDN博客
上一篇文章我们讲解了第一个神经网络的模型,这一篇我们来聊聊梯度下降。
大佬说梯度下降是深度学习的灵魂;梯度是损失函数(代价函数ÿ…
![深度学习与计算机视觉[CS231N] 学习笔记(3.2):Softmax Classifier(Loss Function)](https://img-blog.csdn.net/20180110190019947?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQva3N3czAyOTI3NTY=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
深度学习与计算机视觉[CS231N] 学习笔记(3.2):Softmax Classifier(Loss Function)
在数学,尤其是概率论和相关领域中,Softmax函数,或称归一化指数函数,是逻辑函数的一种推广。它能将一个含任意实数的K维的向量z“压缩”到另一个K维实向量α(z)中,使得每一个元素的范围都在(0,1)}之间,并且所…

损失函数总结(八):MultiMarginLoss、MultiLabelMarginLoss
损失函数总结(八):MultiMarginLoss、MultiLabelMarginLoss 1 引言2 损失函数2.1 MultiMarginLoss2.2 MultiLabelMarginLoss 3 总结 1 引言
在前面的文章中已经介绍了介绍了一系列损失函数 (L1Loss、MSELoss、BCELoss、CrossEntropyLoss、NLL…
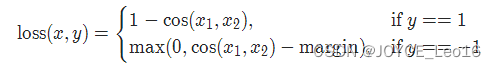
PyTorch内置损失函数汇总 !!
文章目录 一、损失函数的概念 二、Pytorch内置损失函数 1. nn.CrossEntropyLoss 2. nn.NLLLoss 3. nn.NLLLoss2d 4. nn.BCELoss 5. nn.BCEWithLogitsLoss 6. nn.L1Loss 7. nn.MSELoss 8. nn.SmoothL1Loss 9. nn.PoissonNLLLoss 10. nn.KLDivLoss 11. nn.MarginRankingLoss 12. …

softmax函数用于多分类问题的解读
在多分类问题中,我们常常使用softmax作为输出层函数。下面来介绍softmax函数。
1 softmax数学形式:
通过数学表达式,我们可以看到,softmax函数将向量映射为一个概率分布(0,1)对于n维向量最后映…

人工智能|机器学习——机器学习如何判断模型训练是否充分
一、查看训练日志 训练日志是机器学习中广泛使用的训练诊断工具,每个 epoch 或 iterator 结束后,在训练集和验证集上评估模型,并以折线图的形式显示模型性能和收敛状况。训练期间查看模型的训练日志可用于判断模型训练时的问题,例…
人工智能基础_机器学习001_线性回归_多元线性回归_最优解_基本概念_有监督机器学习_jupyter notebook---人工智能工作笔记0040
线性和回归,就是自然规律,比如人类是身高趋于某个值的概率最大,回归就是通过数学方法找到事物的规律. 机器学习作用:
该专业实际应用于机器视觉、指纹识别、人脸识别、视网膜识别、虹膜识别、掌纹识别、专家系统、自动规划、智能搜索、定理证明、博弈、自动程序设计、智能控制…
损失函数总结(三):BCELoss、CrossEntropyLoss
损失函数总结(三):BCELoss、CrossEntropyLoss 1 引言2 损失函数2.1 BCELoss2.2 CrossEntropyLoss 3 总结 1 引言
在前面的文章中已经介绍了介绍了一系列损失函数 (L1Loss、MSELoss)。在这篇文章中,会接着上文提到的众多损失函数继…

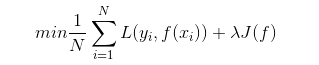
机器学习(一):监督学习、损失函数与风险函数、 经验风险最小化与结构风险最小化
统计学习也称为统计机器学习,希尔伯特西蒙对学习的定义:如果一个系统能过通过执行某个过程改进它的性能,这就是学习。统计学习就是计算机系统通过运用数据及统计方法提高系统性能的机器学习。
统计学习包括监督学习、非监督学习、半监督学习…
【机器学习】各种损失函数
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq547276542/article/details/77980042 常见的损失函数 1.0-1损失函数(0-1 loss function) L(Y,f(X)){1,Y≠f(X)0,Yf(X) L(Y,f(X)){1,Y≠f(X)0,Yf(X) 可以看出&#x…
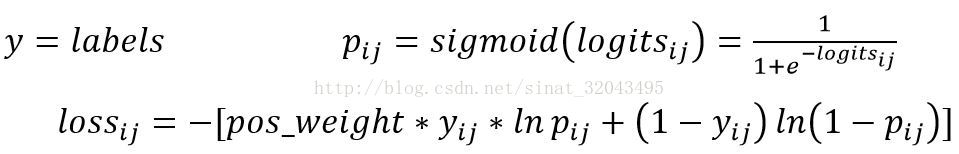
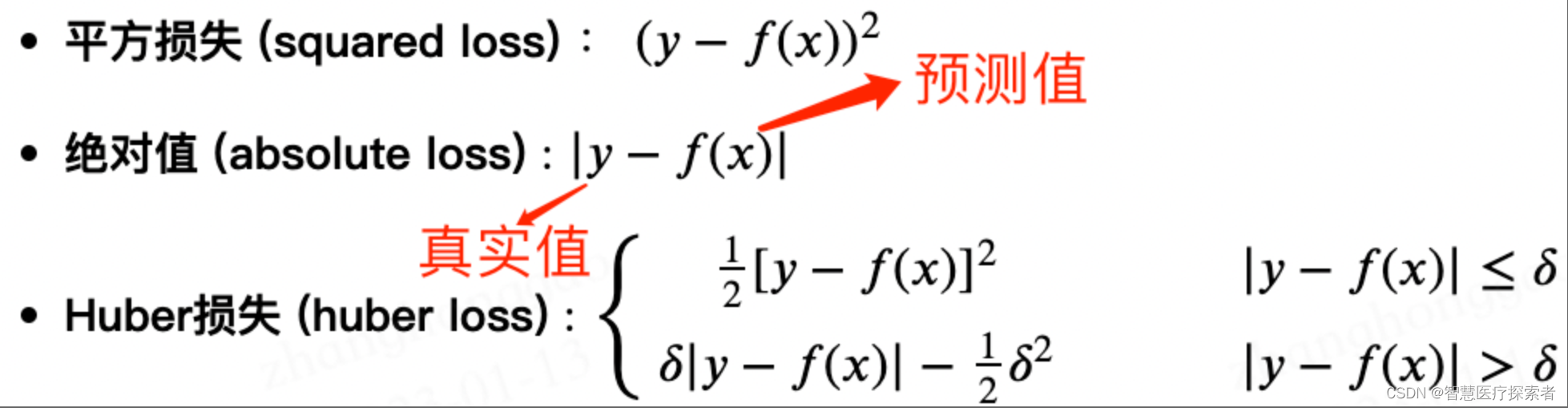
深度学习中的损失函数
1 损失函数概述
大多数深度学习算法都会涉及某种形式的优化,所谓优化指的是改变以最小化或最大化某个函数 的任务,我们通常以最小化指代大多数最优化问题。
在机器学习中,损失函数是代价函数的一部分,而代价函数是目标函数的一种…
机器学习笔记 - 使用具有triplet loss的孪生网络进行图像相似度估计
一、简述 孪生网络是一种网络架构,包含两个或多个相同的子网络,用于为每个输入生成特征向量并进行比较。 孪生网络可以应用于不同的场景,例如检测重复项、发现异常和人脸识别。 此示例使用具有三个相同子网的孪生网络。我们将向模型提供三张图像,其中两张是相似的(锚点和正…

损失函数(MSE和交叉熵)
全连接层解决MNIST:只是一层全连接层解决MNIST数据集 神经网络的传播:讲解了权重更新的过程 这个系列的文章都是为了总结我目前学习的积累。 损失函数
在我文章的网络中,我利用MSE(mean-square error,均方误差&…
损失函数总结(九):SoftMarginLoss、MultiLabelSoftMarginLoss
损失函数总结(九):SoftMarginLoss、MultiLabelSoftMarginLoss 1 引言2 损失函数2.1 SoftMarginLoss2.2 MultiLabelSoftMarginLoss 3 总结 1 引言
在前面的文章中已经介绍了介绍了一系列损失函数 (L1Loss、MSELoss、BCELoss、CrossEntropyLos…
![深度学习与计算机视觉[CS231N] 学习笔记(3.1):损失函数(Loss Function)](https://img-blog.csdn.net/20180110163658691?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQva3N3czAyOTI3NTY=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
深度学习与计算机视觉[CS231N] 学习笔记(3.1):损失函数(Loss Function)
在上一节的线性回归的例子中,我们通过一定的矩阵运算获得了每张图像的最终得分(如下图),可以看到,这些得分有些是比较好的预测,有些是比较差的预测,那么,具体如何定义“好”与“差”…
浅析机器学习中各种损失函数及其含义
常见的损失函数
1.0-1损失函数(0-1 loss function) L(Y,f(X)){1,Y≠f(X)0,Yf(X)L(Y,f(X))=\left\{ \begin{aligned}&1,\quad Y\ne f(X)\\& 0,\quad Y=f(X) \end{aligned} \right.可以看出,该损失函数的意义就是,当预测错误时,损失函…

人工智能基础_机器学习007_高斯分布_概率计算_最小二乘法推导_得出损失函数---人工智能工作笔记0047
这个不分也是挺难的,但是之前有详细的,解释了,之前的文章中有, 那么这里会简单提一下,然后,继续向下学习
首先我们要知道高斯分布,也就是,正太分布, 这个可以预测x在多少的时候,概率最大 要知道在概率分布这个,高斯分布公式中,u代表平均值,然后西格玛代表标准差,知道了
这两个…
损失函数总结(五):PoissonNLLLoss、GaussianNLLLoss
损失函数总结(五):PoissonNLLLoss、GaussianNLLLoss 1 引言2 损失函数2.1 PoissonNLLLoss2.2 GaussianNLLLoss 3 总结 1 引言
在前面的文章中已经介绍了介绍了一系列损失函数 (L1Loss、MSELoss、BCELoss、CrossEntropyLoss、NLLLoss、CTCLos…

RS loss:涨点神器!用于目标检测和实例分割的新损失函数(ICCV2021)
[ICCV2021] RS loss:用于目标检测和实例分割的新损失函数一.论文简介1.1. 简介1.2. RS Loss对简化训练的好处1.3. RS 损失对提高性能的好处二. RS损失的定义2.1. RankSort2.2. aLRPLoss2.3. APLoss三. 在不同模型上的实验结果3.1. 多阶段目标检测3.2. 单阶段目标检测3.3. 多阶段…

激活函数,损失函数,正则化
激活函数简介
在深度学习中,输入值和矩阵的运算是线性的,而多个线性函数的组合仍然是线性函数,对于多个隐藏层的神经网络,如果每一层都是线性函数,那么这些层在做的就只是进行线性计算,最终效果和一个隐藏…

Focal Loss:样本不均衡以及样本难易不同
文章目录现状解决办法方法一、分科复习方法二、刷题战术方法三、综合上述两者调参经验总结现状
先来回顾一下常用的 BinaryCrossEntropyLoss 公式如下 不难看出,CE是个“笨学生”。
考前复习的时候,「他不会划重点,对所有知识点 “一视同仁…

机器学习基础-损失函数,范数
一、统计学中常见的损失函数有以下几种:
1.0-1损失函数(0-1 loss function) L(Y,f(x)){1,Y≠f(X)0,Yf(X)L(Y,f(x)){1,Y≠f(X)0,Yf(X)L(Y,f(x)) = \begin{cases}1, Y \neq f(X)
\\0, Y = f(X)
\end{cases} 2.平方损失函数(quadr…
经验风险最小化与结构风险最小化:优化机器学习模型的两种方法
随着大数据时代的到来,机器学习在各个领域中的应用越来越广泛。然而,在构建机器学习模型时,我们面临着两个主要的挑战:经验风险最小化和结构风险最小化。本文将深入探讨这两种方法,并分析它们在优化机器学习模型中的作…

损失函数和网络优化方法(梯度下降、学习率优化方法)
一、损失函数
1. 概述 用来 衡量模型参数质量的函数,比较网络输出和真实输出的差异,也称为 代价、目标、误差函数: 2. 分类任务的损失函数
(1)多分类 多分类的交叉熵损失 也叫 softmax损失,计算方法&…
损失函数总结(一):损失函数介绍
损失函数总结(一):损失函数介绍 1 引言2 损失函数是什么3 为什么要使用损失函数4 总结 1 引言
在网络模型进行训练时,激活函数、损失函数、优化器都会成为影响模型最终效果的关键因素。其中,激活函数和损失函数根据任…
损失函数总结(六):KLDivLoss、BCEWithLogitsLoss
损失函数总结(六):KLDivLoss、BCEWithLogitsLoss 1 引言2 损失函数2.1 KLDivLoss2.2 BCEWithLogitsLoss 3 总结 1 引言
在前面的文章中已经介绍了介绍了一系列损失函数 (L1Loss、MSELoss、BCELoss、CrossEntropyLoss、NLLLoss、CTCLoss、Poi…

机器学习(15)---代价函数、损失函数和目标函数详解
文章目录 一、各自定义二、各自详解三、代价函数和损失函数区别四、例题理解 一、各自定义 1. 代价函数:代价函数(Cost Function)是定义在整个训练集上的,是所有样本误差的平均,也就是损失函数的平均。它用于衡量模型在…
损失函数总结(十六):NRMSELoss、RRMSELoss
损失函数总结(十六):MSLELoss、RMSLELoss 1 引言2 损失函数2.1 NRMSELoss2.2 RRMSELoss 3 总结 1 引言
在前面的文章中已经介绍了介绍了一系列损失函数 (L1Loss、MSELoss、BCELoss、CrossEntropyLoss、NLLLoss、CTCLoss、PoissonNLLLoss、Ga…
政安晨:【深度学习实践】【使用 TensorFlow 和 Keras 为结构化数据构建和训练神经网络】(三)—— 随机梯度下降
政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 收录专栏: TensorFlow与Keras实战演绎 希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正! 这篇文章中,咱们将使用Keras和TensorFlow…
解析损失函数、代价函数、目标函数
一、损失函数、代价函数、目标函数定义
首先给出结论:
损失函数(Loss Function )是定义在单个样本上的,算的是一个样本的误差。
代价函数(Cost Function )是定义在整个训练集上的,是所有样本…
TensorFlow四种损失函数
Tensorflow交叉熵函数:cross_entropy以下交叉熵计算函数输入中的logits都不是softmax或sigmoid的输出,因为它在函数内部进行了sigmoid或softmax操作tf.nn.sigmoid_cross_entropy_with_logits(_sentinelNone, labelsNone, logitsNone, nameNone)_sentinel…

【AI面试】损失函数(Loss),定义、考虑因素,和怎么来的
神经网络学习的方式,就是不断的试错。知道了错误,然后沿着错误的反方向(梯度方向)不断的优化,就能够不断的缩小与真实世界的差异。
此时,如何评价正确答案与错误答案,错误的有多么的离谱,就需要一个评价指标。这时候,损失和损失函数就运用而生。
开始之前,我们先做…
神经网络中的损失函数(上)——回归任务
神经网络中的损失函数 前言损失函数的含义回归任务中的损失函数平均绝对误差(MAE)L1范数曼哈顿距离优点缺点 均方误差(MSE)均方误差家族L2范数欧氏距离极大似然估计优点缺点 smooth L1 LossHuber 总结 前言
神经网络是深度学习的…
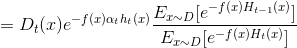
集成学习-AdaBoost更新准则推导 西瓜书
1.损失函数
上一篇文章简单介绍了集成学习和弱学习器的理论概率,最后给出了AdaBoost的伪代码与实现步骤,思路比较清晰,这篇文章主要针对分类器的重要性α与分布权重Dt的更新规则进行推导.推导之前先看一下常见的损失函数(损失函数…